
, поскольку они основываются на комплексной обработке данных и централизации их хранения. Кроме того ЭВМ позволяет хранить любые форматы данных, текст, чертежи, данные в рукописной форме, фотографии, записи голоса и т.д.
Для использования столь огромных объемов хранимой информации, помимо развития системных устройств, средств передачи данных, памяти, необходимы средства обеспечения диалога человек — ЭВМ, которые позволяют пользователю вводить запросы, читать файлы, модифицировать хранимые данные, добавлять новые данные или принимать решения на основании хранимых данных. Для обеспечения этих функций созданы специализированные средства — системы управления базами данных (СУБД).
Современные СУБД — многопользовательские системы управления базой данных, которые специализируется на управлении массивом информации одним или множеством одновременно работающих пользователей.
Современные СУБД обеспечивают:
- набор средств для поддержки таблиц и отношений между связанными таблицами;
- развитый пользовательский интерфейс, который позволяет вводить и модифицировать информацию, выполнять поиск и представлять информацию в графическом или текстовом режиме;
- средства программирования высокого уровня, с помощью которых можно создавать собственные приложения.
Для разработки автоматизированной информационной системы была выбрана интегрированная среда разработки Microsoft Visual FoxPro 6.0 для WINDOWS — приложений. Автоматизированная информационная система предназначена предоставлять оперативную информацию для руководства, подготавливать информацию для дальнейшего анализа, снижать объёмы бумажного документооборота и д.р.
Visual FoxPro 6.0 — одна из наиболее популярных СУБД, кроме того — это объектно-ориентированный, визуально-программируемый язык, управляемый по событиям, который соответствует требованиям, предъявляемым к современным средствам проектирования.
Данная АИС должна работать с оперативными данными, накопление этих данных позволит проводить анализ деятельности предприятия за любой период времени. Это является одной из задач внедрения системы, и для успешного достижения её. Благодаря его использованию, существенно сокращается время, затрачиваемое на подготовку информации для использования в других подсистемах. Это достигается путем выбора наиболее оптимального способа хранения данных в зависимости от типа. При таком подходе, время, затрачиваемое на получение этих данных другими подсистемами также сокращается.
Метрологическая экспертиза и система сертификации средств измерения
... цель метрологической экспертизы нормативно технической документации — анализ рациональности номенклатуры измеряемых параметров, правильности выбора средств измерения, а также оценка влияния погрешностей измерений на технико-экономические показатели эксплуатации технических средств. Перед метрологической экспертизой осуществляют метрологическую проработку, ...
1. Задачи автоматизации учета и анализа продаж
1.1 Постановка задачи
1.1.1 Назначение и цели создание системы
Программное обеспечение для работы с базами данных используется на персональных компьютерах уже довольно давно. К сожалению, эти программы либо были элементарными диспетчерами хранения данных и не имели средств разработки приложений, либо были настолько сложны и трудны, что даже хорошо разбирающиеся в компьютерах люди избегали работать с ними до тех пор, пока не получали полных, ориентированных на пользователя приложений.
Для того чтобы автоматизировать учет складских операций, необходимо решить следующие задачи:
- а) Собрать материал о предприятии;
- б) Проанализировать сущность задач учета складских операций;
- в) Обосновать использование вычислительной техники;
- г) Формализовать расчеты;
- д) Обосновать разработки по всем видам обеспечения;
- е) Построить инфологическую модель;
- ж) Охарактеризовать входную, постоянную, промежуточную и результатную информацию;
- Основное преимущество автоматизации — это сокращение избыточности хранимых данных, а следовательно, экономия объема используемой памяти, уменьшение затрат на многократные операции обновления избыточных копий и устранение возможности возникновения противоречий из-за хранения в разных местах сведений об одном и том же объекте, увеличение степени достоверности информации и увеличение скорости обработки информации; излишнее количество внутренних промежуточных документов, различных журналов, папок, заявок и т.д., повторное внесение одной и той же информации в различные промежуточные документы.
Также значительно сокращает время автоматический поиск информации, который производится из специальных экранных форм, в которых указываются параметры поиска объекта.
Основой задачей данной проектируемой системы является учет и оперативное регулирование хозяйственных операций. Оперативное управление хозяйственными процессами составляет от одного до нескольких дней и реализует регистрацию событий, например приход и расход материальных ценностей на складе и т.д. Эти задачи имеют итеративный, регулярный характер, выполняются непосредственными исполнителями хозяйственных процессов (рабочими, кладовщиками, администраторами и т.д.) и связаны с оформлением и пересылкой документов в соответствии с четко определенными алгоритмами. Результаты выполнения хозяйственных операций регистрируются в соответствующих журналах. Автоматизация этих процессов позволит хранить информацию в одной базе, информация в которую вводится с помощью удобного интерфейса.
Пользователем этой системы будет человек, занимающийся учетом товаров на складах, а также текущей выпиской расходных документов и оприходованием вновь поступивших товаров.
Информационная система позволит избавить сотрудника от рутинной повседневной работы по выписке расходных накладных. Так как раньше документы выписывались в ручную, в которых указывались повторяющиеся реквизиты, а также большой перечень номенклатуры — это занимало много времени. Автоматизация позволит значительно сократить время. Сотруднику нужно будет только выбрать из списка соответствующего клиента и указать номенклатуру из справочника, выбрать дату и отправить на печать документ.
Автоматизация учета расчетов с персоналом по оплате труда на ...
... вопросы, связанные с автоматизацией операций по расчету заработной платы и налогообложению фонда оплаты труда в Российской Федерации. В первой главе дипломной работы рассмотрены теоретические аспекты ведения бухгалтерского учета заработной платы. Во второй главе ...
Чтобы сделать отчет, необходимо собрать нужные данные путем поиска их в соответствующих документах, если это отчет за год, то необходимо будет просмотреть все документы за этот год, на что уйдет огромное количество времени. При выведении итогов по отчету необходима огромная точность в расчетах, что не всегда получается даже у специалиста своего дела. Эти и многие другие задачи сможет решить проектируемая информационная система.
При поиске нужного объекта (суммы, документа, количества), если не будет известен документ, в котором его искать, нужно будет перелистать всю кипу документов и просмотреть каждую позицию. Автоматизация позволит сделать выборку по этой позиции и значительно сократит объем подходящих документов или сведет к одному единственному искомому документу.
За счет сокращения времени на выполнение долгих рутинных работ, можно повысить трудоемкость сотрудника, который может теперь выполнять не только свою работу, но и взять на себя ряд других обязанностей.
Создание собственной автоматизированной системы позволит учесть все особенности, разрабатывается только то, что нужно, и как нужно. Анализ по предприятиям, где уже используются разработанные на стороне программные продукты, показывает, что имеются некоторые проблемы с сопровождением, связанные, прежде всего, с тем, что автоматизируемое предприятие и разработчик находятся в разных городах. В связи с этим, между заказом на какую-либо доработку и результатом проходит, как правило, не менее месяца.
Компьютерная система должна стать не столько помощником, сколько учителем, руководителем и инструментом принуждения необходимых технологии работ. В молодых компаниях начинают с инжиниринга бизнес процессов, так эффект от компьютеризации может кардинально влиять на результативность работы всей компании, если ее только поручить профессионалам реинжиниринга бизнес процессов, предварительно приготовившись к серьезным реформам в организации производственных операций. Но даже самые лучшие программные комплексы не дадут полной отдачи, если их внедрение не поручить специалистам, хорошо разбирающихся в организации управления бизнесом фирмы — заказчика и если высшее руководство не будет сотрудничать с этими специалистами.
Склад, в современной форме, нашел широкое применение в производственных и торговых процессах. На этапе производства какого-либо продукта для обеспечения непрерывности его выпуска необходимо складировать сперва сырье, затем полуфабрикаты, а потом и готовую продукцию.
Под складом понимается специализированное здание, сооружение, устройство, предназначенное для приемки, обработки, хранения и выдачи грузов (товаров) по назначению.
В процессе производства, наряду со средствами труда, участвуют предметы труда, которые выступают в качестве производственных запасов. В отличие от средств труда, предметы труда участвуют в процессе производства только один раз и их стоимость производимой продукции, составляя ее материальную основу.
В общем понимании товарно-материальные запасы — это активы в виде:
- запасов сырья, материалов, покупных полуфабрикатов и комплектующих изделий, топлива, тары и тарных материалов, запасных частей, прочих материалов, предназначенных для использования в производстве или при выполнении работ и услуг;
- незавершенного производства;
- готовой продукции;
- товаров, предназначенных для продажи.
Перед учетом материальных запасов стоят следующие основные задачи: контроль за их своевременным и полным оприходованием, за сохранностью в местах хранения; своевременное и полное документирование всех операций по их движению; правильное определение транспортно-заготовительных расходов и фактической себестоимости заготовленных запасов; контроль за состоянием складских запасов; выявление и организация ненужных субъекту материальных запасов с целью мобилизации внутренних ресурсов; получение точных сведений об остатках и движении запасов в местах их хранения.
Неразрушающий контроль качества материалов и продукции, их эффективность
... катастрофы. Данные о дефектах, полученные на ранних стадиях производства, позволяют техническим службам предприятия совершенствовать технологические процессы, улучшать режимы обработки металла в горячем и холодном состоянии. Применяя методы неразрушающего контроля, ...
В процессе производства материалы учитывают по-разному. Одни из них полностью потребляются в производственном процессе (сырье, материалы, комплектующие изделия, полуфабрикаты и др.), другие — изменяют только свою форму (смазочные материалы, лаки, краски), третьи — входят в изделие без каких-либо внешних изменений (запасные части), четвертые — только способствуют изготовлению изделий и включаются в их массу или химический состав (инструмент, спецодежду и др.).
По функциональной роли и назначению в процессе производства все запасы подразделяются на основные и вспомогательные: основные — это материалы, вещественно входящие в изготовляемую продукцию, образуя ее материальную основу (мука при выпечке хлеба); вспомогательные — эти материалы входят в состав вырабатываемой продукции, но, в отличии от основных, они не создают вещественной(материальной) основы производимой продукции. Их применяют в качестве компонентов к основным материалам для придания продукции необходимых качеств (краски, лак, клей), либо они содействуют производственному процессу.
Деление материалов на основные и вспомогательные условно, поскольку зависит это от количества применения одного и того же материала в разных видах продукции, от характера технологии и других факторов.
Первичные документы по поступлению и расходу производственных запасов являются основой организации материального учета. Непосредственно по первичным документам осуществляют предварительный, текущий и последующий контроль за движением, сохранностью и рациональным использованием товарно-материальных запасов (ТМЗ).
В целях рациональной организации учета и контроля за использованием материалов в производстве при большом ассортименте ТМЗ на предприятиях разрабатывается номенклатура (перечень) потребляемых в производстве материалов по их однородным признакам. Каждому наименованию, сорту материалов присваивается условное цифровое обозначение — номенклатурный номер (код), который затем проставляется во всех документах по наличию и движения ТМЗ.
Для сокращения номенклатуры ТМЗ и упрощения учета в отдельных случаях однородные и близкие по своим свойствам материалы могут объединяться в единый номенклатурный номер. Номенклатурные номера строятся по-разному: они могут быть из шести или девяти знаков и иметь следующую структуру: номер балансового счета, номер группы, номер подгруппы, порядковый номер материалов в подгруппе и т.д.
Номенклатура материалов, в которой указаны цены за единицу учитываемых материалов, называется номенклатурой-ценником. Он представляет собой систематизированный перечень материалов применяемых на предприятии, и используются в качестве справочника всеми отделами предприятия (отдел материально-технического снабжения, бухгалтерия, финансовый и т.д.).
Предприятия могут получать ТМЗ в разных условиях: на складе поставщика, на станции железной дороги, на пристани, в аэропорту или непосредственно в своем складском помещении, где их принимает материально-ответственное лицо.
Проанализировав деятельность фирмы, видно, что склад для предприятия имеет очень важное значение.
Чтоб предприятие полноценно функционировало необходимо вести тщательный учет.
Целью разработанной информационной системы, где в качестве клиента выступают поставщики склада, стала организация эффективной работы компьютерной системы, организация компьютеризации документооборота, учетных операций, развитие компьютеризации для поддержания управление предприятием на уровне современных требований.
Создав удобный пользовательский интерфейс (меню, формы), требуется обеспечить решение следующих задач:
- Ввод, корректировка, просмотр входных данных;
- Анализ и обработку данных;
- Формирование необходимых запросов и отчетов с возможностью вывода результатов на экран монитора или принтер.
1.1.2 Требования к разрабатываемой информационной системе
Ядром информационной системы являются хранимые данные. На любом предприятии данные различных отделов, как правило, пересекаются. Например, для целей управления часто нужна информация по всему предприятию. Принятие решений по производственным вопросам невозможно без информации о товарах, о полученных заказах, о стратегии сбыта и т.д. Это означает, что описывающие конкретную предметную область данные должны храниться в легко доступном виде.
Чтобы принять процесс электронной обработки данных, необходимо знать ряд терминов, которые применяются при описании и представлении данных (таблица 1.1).
Предметная область. Предметная область может относиться к любому типу организации (например, банк, университет, больница или завод).
Необходимо различать полную предметную область (крупное предприятие по производству автомобилей, ЭВМ, химической продукции или по выплавке стали) и организационную единицу этой предметной области. Организационная единица в свою очередь может представлять свою предметную область (например, цех по производству кузовов автомобильного завода или отдел обработки данных предприятия по производству ЭВМ).
В данном случае цеха и отделы сами могут соответствовать определенным предметным областям. Объект. Объектом может быть человек, предмет, событие, место или понятие, о котором записаны данные.
Атрибут. Каждый объект характеризуется рядом основных атрибутов. Например, дом характеризуется габаритами, цветом, временем эксплуатации и размером приусадебного участка. Клиент банка имеет такие атрибуты, как фамилию, адрес и, возможно, идентификационный номер. Атрибут часто называют элементом данных, полем данных, полем данных или элементарным. Значение данных. Значение данных представляет действительные данные, содержащиеся в каждом элементе данных.
Информацию о некоторой предметной области можно представить с помощью нескольких объектов, каждый из которых описывается несколькими элементами данных. Принимаемые элементами данных значения называются данными. Единичный набор принимаемых элементами данных значений называются экземпляром объекта. Объекты связываются между собой определенным образом. Соответствующая модель объектов с составляющими их элементами данных и взаимосвязями называются концептуальной моделью. Концептуальная модель дает общее представление о потоке данных в предметной области.
При рассмотрении данных часто бывает трудно выявить различия между объектом, элементом данных и значением элемента данных.
Ключевой элемент данных. Некоторые элементы данных обладают интересными свойствами. Зная значение, которое принимает такой элемент данных объекта, мы можем идентифицировать значения, которые принимают другие элементы данных этого же объекта. Элементы данных, по которым можно определить другие элементы данных, называются ключевыми. Иногда их называют также идентификатором объекта.
Однозначно идентифицировать объект могут два и более элемента данных. В этом случае их называют «кандидатами» в ключевые элементы данных. Вопрос о том, какой из кандидатов использовать для доступа к объекту, решается пользователем или проектировщиком. Выбирать ключевые элементы данных следует тщательно, поскольку правильный выбор способствует созданию достоверной модели данных.
Таблица 1.1 — Основные термины реляционной модели
|
Термин |
Альтернативный термин |
Приблизительный эквивалент |
|
Отношение |
Таблица |
Файл (один тип записи, фиксированное число типов полей) |
|
Атрибут Первичный ключ |
Столбец |
Поле (тип, а не экземпляр) |
|
Кортеж Домен |
Строка |
Ключ записи, идентификатор записи Запись (экземпляр, а не тип) |
Можно сформулировать ряд требований к разрабатываемой информационной системе.
Требования, которым должна удовлетворять СУБД:
— эффективное выполнение одной и той же СУБД различных функций предметной области;
— минимизация избыточности хранимых данных;
предоставление для процессов принятие решений непротиворечивой информации;
обеспечение управления безопасностью;
отсутствие повышенных требований к персоналу, связанному с разработкой, поддержанием и совершенствованием прикладных программ при большой производительности и меньших затратах;
простая физическая реорганизация базы данных;
возможность централизованного управления базой данных;
упрощение процедуры эксплуатации ЭВМ.
С базой данных взаимодействуют несколько пользователей. Поэтому крайне необходима функция учета различных требований и разрешения конфликтов. Иными словами, нужно ввести долгосрочную функцию администрирования, направленную на координацию и выполнение всех этапов проектирования, реализации и ведения интегрированной базы данных, в соответствии с которой на определенных лиц возлагается ответственность за сохранность важного ресурса — данных.
Лицо, ответственное за выполнение функции администрирования базы данных, называется администратором базы данных.
При рассмотрении требований конечных пользователей необходимо принимать во внимание следующее:
База данных должна удовлетворять актуальным информационным потребностям.
— База данных должна удовлетворять актуальным требованиям за приемлемое время, т.е. заданным требованиям производительности.
— База данных должна удовлетворять выявленным и вновь возникающим требований конечных пользователей.
База данных должна легко расширяться при реорганизации и расширении предметной области.
База данных должна легко изменяться при изменении программной и аппаратной среды.
Загруженные в базу данных корректные данные должны оставаться корректными.
Данные до включения в базу данных должны проверяться на достоверность.
Доступ к данным, размещаемым в базе данных, должны иметь только лица с соответствующими полномочиями.
1.2 Выводы
Для разработки действительно эффективной автоматизированной информационной системы в первую очередь необходимо определиться с назначением и целью создания системы, а также требованиями к ней. Что и было сделано.
Целью разработанной информационной системы стала организация эффективной работы компьютерной системы, организация компьютеризации документооборота, учетных операций.
Создав удобный пользовательский интерфейс (меню, формы), требуется обеспечить решение следующих задач:
— Ввод, корректировка, просмотр входных данных;
— Анализ и обработку данных;
— Формирование необходимых запросов и отчетов с возможностью вывода результатов на экран монитора или принтер;
Были сформулированы следующие требования к разрабатываемой информационной системе:
— эффективное выполнение одной и той же СУБД различных функций предметной области;
— минимизация избыточности хранимых данных;
предоставление для процессов принятие решений непротиворечивой информации;
обеспечение управления безопасностью;
отсутствие повышенных требований к персоналу, связанному с разработкой, поддержанием и совершенствованием прикладных программ при большой производительности и меньших затратах;
простая физическая реорганизация базы данных;
возможность централизованного управления базой данных;
упрощение процедуры эксплуатации ЭВМ.
Можно сформулировать ряд требований к разрабатываемой информационной системе.
Требования, которым должна удовлетворять СУБД:
эффективное выполнение одной и той же СУБД различных функций предметной области;
— минимизация избыточности хранимых данных;
предоставление для процессов принятие решений непротиворечивой информации;
обеспечение управления безопасностью;
отсутствие повышенных требований к персоналу, связанному с разработкой, поддержанием и совершенствованием прикладных программ при большой производительности и меньших затратах;
простая физическая реорганизация базы данных;
возможность централизованного управления базой данных;
упрощение процедуры эксплуатации ЭВМ.
2. Разработка информационной системы учета и анализа продаж
2.1 Описание структуры базы данных
2.1.1 Анализ информационных потоков
Сбор информации о данных является трудоемкой задачей и требует непременного участия руководства. Разработчик должен разработать план проведения обследования предприятия. С помощью вопросника или иного подобного средства ему нужно составить списки данных, необходимые работникам всех уровней управления (исполнительного, функционального и эксплуатационного).
Причем на различных уровнях данные могут обрабатываться или накапливаться. Затем разработчику предстоит проанализировать все направления использования данных на предприятии.
Сбор данных следует начинать с изучения существующих форм документов, отчетов, имеющихся файлов и программ. Основной вопрос, требующий первоочередного решения, — какие именно данные должны быть представлены в базе данных. При этом необходимо учитывать, что подлежащие хранению данные редко однозначно соответствуют данным, отображаемым в формах и отчетах.
Каждый руководитель или сотрудник предприятия, который пользуется данными или участвует в их подготовке, должны заполнить соответствующую анкету. При этом чрезвычайно важно, чтобы ответственность за заполнение анкет несло руководство, поскольку анкеты отражают перспективные информационные потребности предприятия. В процессе сбора исходных данных следует предусмотреть дополнительные формы проведения опроса, чтобы дать возможность сотрудникам дополнить первоначальные списки требуемых данных, особенно тем, кто еще не был опрошен. Это существенный момент: если опрашивались не все сотрудники организации необходимо пересмотреть модель предметной области и выяснить, почему в списке опрашиваемых лиц имеются пробелы.
Анкеты должны содержать: имя объекта данных, имя элемента данных, описания, атрибуты, источники, уровни конфиденциальности, показатель важности, а также взаимосвязи между элементами и между объектами. Заполняющий анкету должен включать в нее как можно больше сведений, хотя может оказаться, что один человек будет не в состоянии заполнить все ее статьи. Тем не менее не следует полагаться на то, что незаполненные статьи вследствие будут заполнены другими лицами. Полное и точное представление о данных предметной области может быть получено только в том случае, если на предложенные в анкете вопросы каждый пользователь даст исчерпывающие ответы.
Анкета может состоять из следующих вопросов:
1. Имя и описание объекта данных. Указываются основное имя и синонимы. Дается вербальное описание смыслового содержания имени, даже если его смысл представляется очевидным. В общих чертах описывается функциональное назначение и использование объекта в функциональных и структурных подразделениях предприятия, а также за их пределами.
2. Элементы данных. Для каждого элементарного данного, входящего в конкретный объект, указывается:
a) Его имя и описание. Перечисляются имена, акронимы и дается их расшифровка. Приводится полное вербальное описание элемента;
b) Источник. Перечисляются источники элемента в структуре предприятия;
- Атрибуты. Указываются тип значения атрибута (числовой, текстовой, дата), единицы измерения, а при необходимости и допустимые диапазоны значений;
- Использование элемента данных;
- Ограничение безопасности / чувствительности. Перечисляются связанные с данным элементом ограничения, включая допущенных к нему лиц и разрешенный им вид обработки;
- Степень важности. Указывается степень важности данного элемента. Она должна определяться значением элемента данных для реализации или расширения функций предприятия;
- Взаимосвязи элемента данных. Описываются способы совместного использования данного элемента с другими, не обязательно принадлежащих рассматриваемому объекту
3. Продолжительность хранения и условия перевода в архив. Указывается период времени, в течение которого должны храниться значения элемента данных, и способ хранения (правительственные распоряжения, указания администрации предприятия).
Одновременно с проведением анкетирования разработчик должен исследовать информационные потоки в аппарате управления, в канцелярии, при обработке данных. Целью такого исследования является не столько проверка правильности заполнения анкет, сколько разработка модели предприятия. В результате разработчик получает представление о документообороте предприятия, определяет пути и способы передачи данных.
Следующий и, вероятно, наиболее важный этап — анализ организации хранения данных, базирующийся на результатах анкетирования и исследования документооборота. Этот анализ достаточно просто описывается, но не так легко выполняется. Разработчик заполняет таблицу, где указывает условно-постоянные данные, оперативные и выходные данные.
Сбор информации для планирования перспективного использования базы данных — одна из наиболее важных и сложных задач разработчика. Обычно после ввода базы данных в эксплуатацию пользователи, оценив на практике ее значение для принятия решений и обработки информации, предъявляют более высокие требования к составу реализуемых функций, вносят предложения по введению новых перекрестных ссылок и улучшению операционных характеристик системы. Если основу проектирования составляют только текущие требования к базе данных, то это может затруднить реализацию новых. Для того, чтобы подобные проблемы в будущем не возникали, разработчик должен заранее учитывать возможные пути использования информации. Это достаточно трудно, но тем не менее разработчику приходится выявлять неучтенные объекты и взаимосвязи, которые могут и не быть задействованы ни в каких функциях, и детально обсуждать их с пользователями.
Анализируя информационные потоки складского учета на предприятии, выявили следующие данные (рисунок 2.1):
Условно-постоянные данные (справочники):
— Наименование товара,
— Ед. измерения, категория товара,
— Склад (номер склада, или его название),
— Перечень организаций, поставляющих товар и их реквизитов,
— Ф.И.О. кладовщика.
Оперативные данные:
— цена товара,
— количество приход,
— количество расход,
— № накладной,
— дата прихода товара,
— остатки,
— сумма налога [12% от сто-ти товара],
— к оплате [сумма+налог].
— Сумма налога за текущий месяц по приходу и расходу.
— Список категорий товаров, хранящихся на i-ом складе.
— Какой товар на складе находится в минимальном количестве.
— Приходная ведомость по i-му складу за j-ое число.
— Ведомость движения товара (остаток — приход — расход — остаток)] по i-му складу.
— Сведения об общей сумме прихода / расхода товаров в I-ом месяце по категориям.
Рисунок 2.1 — Информационные потоки
2.1.2 Инфологическая модель
Данные в реляционной модели данных представляются в виде таблицы. В терминологии реляционной модели таблица, называется отношением. Чтобы не смешивать отношения с взаимосвязями между объектами, иногда мы будем называть отношение таблицей. Каждый столбец в таблице является атрибутом. Значение в столбце выделяются из домена, т.е. домен суть множества значений, который может принимать некоторый атрибут. Строки таблицы называются картежами.
В соответствии с традиционной терминологии можно сказать, что столбцы таблицы представляют элементы данных, а строки — записи.
Столбец или ряд столбцов называются возможным ключом отношения, если его (их) значения однозначно идентифицируют строки таблицы. Основные термины реляционной модели приведены на рисунке. Вполне вероятно, что отношение имеет более одного ключа. В этом случае удобно рассматривать один из ключей в качестве первичного.
Если столбцам присвоены уникальные имена, то порядок их следования не имеет значения. В таблице не может существовать одинаковых строк. Способ упорядочивания таблицы также несущественен. Свойства отношений представлены ниже:
1. Отсутствуют одинаковые строки.
2. Порядок строк не существенен.
. Порядок столбцов не существенен (предполагается, что каждый столбец имеет уникальное имя).
. Все значения имеют атомарный характер, т.е. их нельзя разбить на компоненты (без потери информации).
Одним из главных достоинств реляционного подхода является его простата, а отсюда — и доступность для понимания конечным пользователем. Конечные пользователи не имеют дела с физической структурой памяти. Вместо этого они могут сосредоточиться на содержательной стороне проблемы. Возможность эксплуатации базы данных без знания деталей ее построения называется независимостью данных.
Для обеспечения связи между таблицами некоторые из них должны содержать общие атрибуты. В результате между некоторыми таблицами возникает избыточность по ключу. Однако это не обязательно приводит к физической избыточности, поскольку таблицы отражают логическое представление пользователя.
Достоинства модели.
Простота. Пользователь работает с простой моделью данных. Он формулирует запросы в терминах информационного содержания и не должен принимать во внимание сложные объекты системной реализации. Реляционная модель отражает представление пользователя, но она не обязательно лежит в основе физической реализации.
Непроцедурные запросы. Поскольку в реляционной схеме понятие навигации отсутствует, запросы не строятся на основе заранее определенной структуры. Благодаря этому они могут быть сформулированы на непроцедурном языке.
Независимость данных. Это свойство является одним из важнейших для любой СУБД. При использовании реляционной модели данных интерфейс пользователя не связан с деталями физической структуры данных и стратегией доступа. Модель обеспечивает относительно высокую степень независимости данных по сравнению с двумя другими рассматриваемыми моделями. Для эффективного использования этого свойства, однако, необходимо проектировать схему отношений весьма тщательно.
Теоретическое обоснование. Реляционная модель данных основана на хорошо проработанной теории отношений. При проектировании базы данных применяются строгие методы, построенные на нормализации отношений.
В процессе нормализации элементы данных группируются в таблицы, представляющие объекты и их взаимосвязи. Теория нормализации основана на том, что определенный набор отношений обладает лучшими свойствами при включении, модификации и удалении данных, чем все остальные наборы отношений, с помощью которых могут быть представлены те же данные.
Ненормализованная модель данных включает записи в том виде, в котором они используются прикладными программами.
Первый шаг при нормализации заключается в образовании двумерной таблицы, содержащей элементы данных. Для этого практически нужно лишь исключить повторяющиеся группы.
Второй шаг нормализации состоит в том, чтобы выделить ключи и зависящие от них атрибуты. Каждый кортеж отношений, находящийся в первой нормальной форме, полностью зависит от совокупности ключевых атрибутов. Для того чтобы привести отношения ко второй нормальной форме, нужно выделить группу атрибутов, зависящие от частей составного ключа. Эти группы могут образовать отдельные отношения (таблицы).
Выделение из отношения, находящегося в первой нормальной форме, таких отношений, в которых не ключевые атрибуты зависят только от ключа в целом, называется приведением ко второй нормальной форме.
На третьем шаге нормализации следует выделить из отношений, находящихся во второй нормальной форме, те атрибуты, которые, хотя и зависят от ключа какого-либо отношения, тем не менее могут существовать в базе данных независимо от остальных атрибутов этого отношения. Выделение атрибутов позволяет вводить их значения вне зависимости от взаимосвязей, в которых они участвуют.
В любой модели данных для представления объектов и их взаимосвязей необходимо некоторым образом сгруппировать элементы данных. При обработки групп элементов возникают три общих проблемы. Устранение этих проблем требует приведения отношений к одной из трех нормальных форм. Таким образом, процесс нормализации, выполняемой по определенным правилам, состоит в группировке элементов данных в ряде отношений.
Все нормализованные отношения находятся в первой нормальной форме. Ряд отношений первой нормальной формы находятся во второй нормальной форме и, наконец, некоторые из отношений второй нормальной формы находятся в третьей нормальной форме. Цель процесса нормализации — приведение отношений к третьей нормальной форме. Отношения в третьей нормальной форме представляют объекты и взаимосвязи между объектами рассматриваемой предметной области.
Процесс нормализации позволяет проектировщику глубже понять семантику атрибутов и их взаимосвязей и упорядочивает проведение анализа данных.
Первая нормальная форма.
Отношение, находящееся в первой нормальной форме, представляет собой таблицу. На пересечении столбца и строки может быть только одно значение. Существование групп значений на пересечении строк и столбцов не допускается.
Вторая нормальная форма.
Отношение находится во второй нормальной форме, если все не ключевые атрибуты полностью функционально зависят от первичного ключа, или другими словами, для однозначной идентификации каждого не ключевого атрибута требуется весь первичный ключ.
Всякое отношение во второй нормальной форме одновременно является и отношением в первой нормальной форме.
Третья нормальная форма.
Отношение находится в третьей нормальной форме, если устранена функциональная транзитивная зависимость между не ключевыми атрибутами.
Система управления базами данных (СУБД) основывается на использовании определенной модели данных. Модель данных отражает взаимосвязи между объектами. Большинство современных реализаций баз данных применяют иерархическую или сетевую модель. Однако все большее значение приобретает реляционная модель данных.
Описание нормализации таблиц
Каждой нормальной форме соответствует некоторый определенный набор ограничений, и таблица находится в какой-либо нормальной форме, если удовлетворяет свойственному ей набору ограничений.
. Таблица Товары находится в первой нормальной форме т.к. ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Таблица Товары находится в третьей нормальной форме т.к. она удовлетворяет определению второй нормальной формы и не одно из ее не ключевых полей не зависит функционально от любого другого не ключевого поля.
. Таблица Остатки находится в первой нормальной форме т.к. ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Таблица Остатки находится в третьей нормальной форме т.к. она удовлетворяет определению второй нормальной формы и не одно из ее не ключевых полей не зависит функционально от любого другого не ключевого поля.
. Таблица Категории товара находится в первой нормальной форме т.к. ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Таблица Категории товара находится в третьей нормальной форме т.к. она удовлетворяет определению второй нормальной формы и не одно из ее не ключевых полей не зависит функционально от любого другого не ключевого поля.
. Таблица Организации находится в первой нормальной форме т.к. ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
. Таблица Движение находится в первой нормальной форме т.к. ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Таблица Движение находится в третьей нормальной форме т.к. она удовлетворяет определению второй нормальной формы и не одно из ее не ключевых полей не зависит функционально от любого другого не ключевого поля.
. Таблица Склад находится в первой нормальной форме т.к. ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
. Таблица Таксировка находится в первой нормальной форме т.к. ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Таблица Таксировка находится в третьей нормальной форме т.к. она удовлетворяет определению второй нормальной формы и не одно из ее не ключевых полей не зависит функционально от любого другого не ключевого поля.
. Таблица Единицы измерения находится в первой нормальной форме т.к. ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто.
Таблица Единицы измерения находится в третьей нормальной форме т.к. она удовлетворяет определению второй нормальной формы и не одно из ее не ключевых полей не зависит функционально от любого другого не ключевого поля.
Одна из главных функций администрирования базы данных состоит в разработке модели предметной области. Компонентами модели являются объекты и их взаимосвязи. Модель служит средством общения между различными пользователями и поэтому разрабатывается без учета особенностей физического представления данных. Модель предметной области используется для выражения, организации, упорядочения и обмена представлениями. Она не зависит от применяемой СУБД (рисунок 2.2).
Взаимосвязь выражает отображение или связь между двумя множествами данных. Различают взаимосвязи типа «один к одному», «один ко многим» и «многие ко многим».
В случае разрабатываемой АИС используются связи типа «один ко многим». Например, Сокращение «штука» из таблицы Единицы измерения встречаются несколько раз в Изделии.
Объединяя частные представления о содержимом базы данных, полученные в результате опроса пользователей, и свои представления о данных, которые могут потребоваться в будущих приложениях, проектировщик сначала создает обобщенное неформальное описание создаваемой базы данных. Это описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающим над проектированием базы данных, называют инфологической моделью данных. Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. Остальные модели являются компьютерно-ориентированными. С их помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Так как указанный доступ осуществляется с помощью конкретной СУБД, то модели должны быть описаны на языке описания данных этой СУБД. Такое описание, созданное проектировщиком БД по инфологической модели данных, называют даталогической моделью данных.
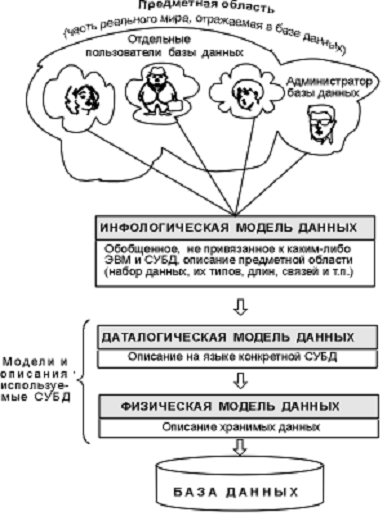
Рисунок 2.2 — Этапы проектирования БД
Цель инфологического моделирования — обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты).
Сущность — любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе.
Атрибут — поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей. Атрибуты используются для определения того, какая информация должна быть собрана о сущности.
Ключ — минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности.
Связь — ассоциирование двух или более сущностей.
При построении инфологических моделей можно использовать язык ER-диаграмм (от англ. Entity-Relationship, т.е. сущность-связь), язык инфологического моделирования (ЯИМ) и языка «Таблицы — связи».
В языке ER-диаграмм сущности изображаются помеченными прямоугольниками, ассоциации — помеченными ромбами или шестиугольниками, характеристики — трапециями, атрибуты — помеченными овалами, а связи между ними — ненаправленными ребрами, над которыми может проставляться степень связи (1 или буква М, заменяющая слово «много») и необходимое пояснение.диаграмма модели показана на рисунке 2.1.
Чаще же применяется менее наглядный, но более содержательный язык инфологического моделирования (ЯИМ), в котором сущности и ассоциации представляются предложениями вида:
СУЩНОСТЬ (атрибут 1, атрибут 2,…, атрибут n)
АССОЦИАЦИЯ [СУЩНОСТЬ S1, СУЩНОСТЬ S2,…]
(атрибут 1, атрибут 2,…, атрибут n)
где S — степень связи, а атрибуты, входящие в ключ, должны быть отмечены с помощью подчеркивания.
Классификация сущностей. К. Дейт определяет три основные класса сущностей: стержневые, ассоциативные и характеристические, а также подкласс ассоциативных сущностей — обозначения.
Стержневая сущность (стержень) — это независимая сущность.
Ассоциативная сущность (ассоциация) — это связь вида «многие-ко-многим» (» — ко-многим» и т.д.) между двумя или более сущностями или экземплярами сущности. Ассоциации рассматриваются как полноправные сущности: они могут участвовать в других ассоциациях и обозначениях точно так же, как стержневые сущности; могут обладать свойствами, т.е. иметь не только набор ключевых атрибутов, необходимых для указания связей, но и любое число других атрибутов, характеризующих связь
Характеристическая сущность (характеристика) — это связь вида «многие-к-одной» или «одна-к-одной» между двумя сущностями (частный случай ассоциации).
Единственная цель характеристики в рамках рассматриваемой предметной области состоит в описании или уточнении некоторой другой сущности. Необходимость в них возникает в связи с тем, что сущности реального мира имеют иногда многозначные свойства.
Обозначающая сущность или обозначение — это связь вида «многие-к-одной» или «одна-к-одной» между двумя сущностями и отличается от характеристики тем, что не зависит от обозначаемой сущности.
Для наиболее распространенных реляционных баз данных можно предложить язык инфологического моделирования «Таблица-связь» (рисунке 2.2).
В нем все сущности изображаются одностолбцовыми таблицами с заголовками, состоящими из имени и типа сущности. Строки таблицы — это перечень атрибутов сущности, а те из них, которые составляют первичный ключ, распологаются рядом и обводятся рамкой. Связи между сущностями указываются стрелками, направленными от первичных ключей или их составляющих.
Анализируя исходные данные можно выделить стержни, характеристики, обозначения, ассоциации и построить инфологическую модель на языке «ER-Диаграммы представленную на рис. 2.3.
2.1.3 Даталогическая модель
После построения инфологической модели данных, выполнив следующие шаги, строиться даталогическая модель.
1. Представляем каждый стержень (независимую сущность) таблицей базы данных (базовой таблицей) и специфицируем первичный ключ этой базовой таблицы.
2. Представляем каждую ассоциацию (связь вида «многие-ко-многим» между сущностями) как базовую таблицу. Используем в этой таблице внешние ключи для идентификации участников ассоциации и специфицируем ограничения, связанные с каждым из этих внешних ключей.
3. Представляем каждое свойство как поле в базовой таблице, представляющей сущность, которая непосредственно описывается этим свойством.
4. Для того чтобы исключить в проекте непреднамеренные нарушения каких-либо принципов нормализации, выполним процедуру нормализации.
5. Если в процессе нормализации было произведено разделение каких-либо таблиц, то следует модифицировать инфологическую модель базы данных и повторить перечисленные шаги.
6. Указать ограничения целостности проектируемой базы данных и дать (если это необходимо) краткое описание полученных таблиц и их полей.
СОЗДАТЬ ТАБЛИЦУ Товары *(Стержневая сущность. Связывает Категории товара, Остатки и Движения)
ПЕРВИЧНЫЙ КЛЮЧ (Код товара)
ВНЕШНИЙ КЛЮЧ (Код категории из Категория товара
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Категория товара Restrict
ОБНОВЛЕНИЕ Категория товара. Код категории КАСКАДНОЕ)
ПОЛЯ (Код товара Целое, Наименование Текст 80, Цена Денежное, Ед. измерения Текст 8, Код категории Целое)
ОГРАНИЧЕНИЯ (1. Значения поля Код категории должно принадлежать набору значений из соответствующего поля таблицы Категория товара.
2. Значения полей Код товара, Цена должны принимать только положительные значения; при нарушении вывод сообщения «Код товара (Цена) может принимать только положительные значения»).
СОЗДАТЬ ТАБЛИЦУ Остатки *(Связывает Товары и Склад)
ВНЕШНИЙ КЛЮЧ (Код товара из Товары
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Товары Restrict
ОБНОВЛЕНИЕ Товары. Код товара КАСКАДНОЕ)
ВНЕШНИЙ КЛЮЧ (Код Склада из Склад
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Склад Restrict
ОБНОВЛЕНИЕ Склад. Код склада КАСКАДНОЕ)
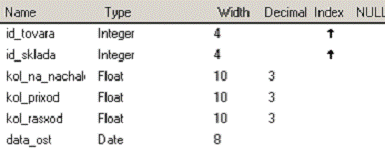
ПОЛЯ (Код товара Целое, Код склада Целое, Количество на начало Дробное, Количество приход Дробное, Количество расход Дробное, Количество на конец Дробное, Дата Дата)
ОГРАНИЧЕНИЯ (1. Значения полей Код товара и Код склада должны принадлежать набору значений из соответствующих полей таблиц Товары и Склад
2. Значения полей Количество на начало, Количество приход, Количество расход, должны принимать только положительные значения; при нарушении вывод сообщения «Количество на начало (Количество прихода, Количество расхода) может принимать только положительные значения»)
СОЗДАТЬ ТАБЛИЦУ Категории товара
ПЕРВИЧНЫЙ КЛЮЧ (Код категории)
ПОЛЯ (Код категории Целое, Наименование Текст 20)
ОГРАНИЧЕНИЯ (1. Значения поля Код категории должны принимать только положительные значения; при нарушении вывод сообщения «Код категории может принимать только положительные значения»).
СОЗДАТЬ ТАБЛИЦУ Организации *(Связывает Таксировка и Движение)
ПЕРВИЧНЫЙ КЛЮЧ (Код организации)
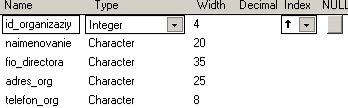
ПОЛЯ (Код организации Целое, Наименование Текст 20, Ф.И.О. Директора Текст 35, Адрес Текст 25, Телефон Текст 8)
ОГРАНИЧЕНИЯ (1. Значения поля Код организации должны принимать только положительные значения; при нарушении вывод сообщения «Код организации может принимать только положительные значения»).
СОЗДАТЬ ТАБЛИЦУ Движение *(Связывает Организации, Склад и Товары)
ПЕРВИЧНЫЙ КЛЮЧ (№ накладной)
ВНЕШНИЙ КЛЮЧ (Код Склада из Склад
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Склад Restrict
ОБНОВЛЕНИЕ Склад. Код склада КАСКАДНОЕ)
ВНЕШНИЙ КЛЮЧ (Код организации из Организации
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Организации Restrict
ОБНОВЛЕНИЕ Организации. Код организации КАСКАДНОЕ)
ВНЕШНИЙ КЛЮЧ (Код товара из Товары
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Товары Restrict
ОБНОВЛЕНИЕ Товары. Код товара КАСКАДНОЕ)
ПОЛЯ (№ накладной Целое, Код товара Целое, Цена Денежное, Код склада Целое, Дата Дата, Приход/расход Целое, Количество Дробное, Код организации Целое)
ОГРАНИЧЕНИЯ (1. Значения полей Код товара, Код организации и Код склада должны принадлежать набору значений из соответствующих полей таблиц Товары, Организации и Склад
. Значения полей № накладной, Количество, должны принимать только положительные значения; при нарушении вывод сообщения «Код Движения (Количество) может принимать только положительные значения»)
СОЗДАТЬ ТАБЛИЦУ Склад *(Связывает Остатки и Движение)
ПЕРВИЧНЫЙ КЛЮЧ (Код Склада)
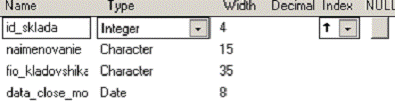
ПОЛЯ (Код склада Целое, Наименование Текст 15, Ф.И.О. кладовщика Текст 35)
ОГРАНИЧЕНИЯ (1. Значения поля Код Склада должны принимать только положительные значения; при нарушении вывод сообщения «Код склада может принимать только положительные значения»).
СОЗДАТЬ ТАБЛИЦУ Таксировка
ВНЕШНИЙ КЛЮЧ (Код организации из Организации
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Организации Restrict
ОБНОВЛЕНИЕ Организации. Код организации КАСКАДНОЕ)
ВНЕШНИЙ КЛЮЧ (№ накладной из Движения
NULL-значения НЕ ДОПУСТИМЫ
УДАЛЕНИЕ ИЗ Движения КАСКАДНОЕ
ОБНОВЛЕНИЕ Движения. №накладной КАСКАДНОЕ)
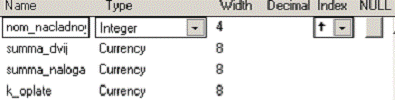
ПОЛЯ (№ накладной Целое, Сумма Денежное, Сумма налога Денежное, К оплате Денежное)
ОГРАНИЧЕНИЯ (1. Значения поля (№ накладной должно принадлежать набору значений из соответствующего поля таблицы Движение).
СОЗДАТЬ ТАБЛИЦУ Единицы измерения
ПЕРВИЧНЫЙ КЛЮЧ (Код единицы измерения)
ПОЛЯ (Код единицы измерения Целое, Наименование Текст 10)
ОГРАНИЧЕНИЯ (1. Значения поля Код единицы измерения должны принимать только положительные значения; при нарушении вывод сообщения «Код единицы измерения может принимать только положительные значения»).
2.2 Создание, описание структуры и свойств БД, определение отношений между таблицами и условий целостности данных
2.2.1 Описание структуры БД
1. Разработку БД в среде Visual FoxPro начинаем с созданием проекта Course.pjx, структура которого представлена на рисунке 2.4.
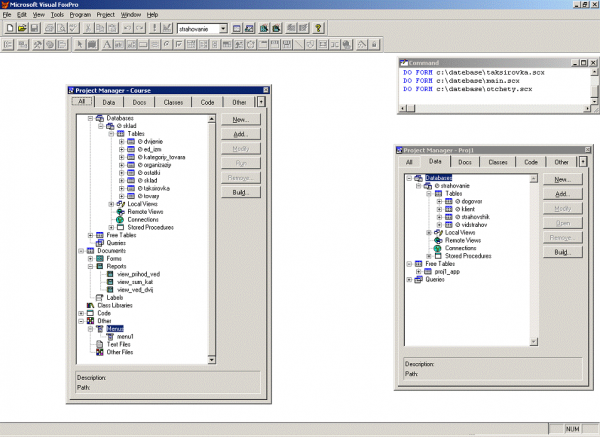
Рисунок 2.4 — Структура проекта
Проект Course включает в себя следующие компоненты: БД Course, таблицы, хранимые процедуры, запросы, формы, отчеты, меню, программы.
2.2.2 Описание свойств таблиц БД
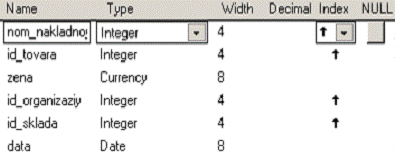
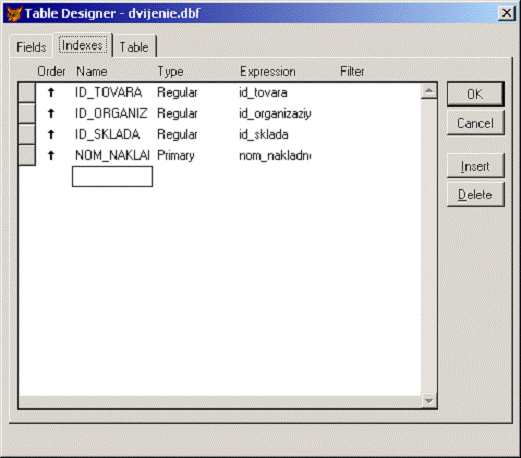
1. Таблица dvijenie.dbf со структурой
Индексация таблицы
2. Таблица ed_izm.dbf со структурой

Индексация таблицы

3. Таблица kategoriy_tovara.dbf со структурой

Индексация таблицы
![]()
4. Таблица organizaziy.dbf со структурой
Индексация таблицы
![]()
5. Таблица ostatki.dbf со структурой
![]()
Индексация таблицы

6. Таблица sklad.dbf со структурой
Индексация таблицы
![]()
7. Таблица taksirovka.dbf со структурой
Индексация таблицы
![]()
8. Таблица tovary.dbf со структурой
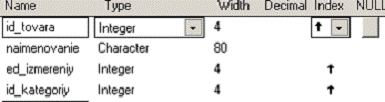
Индексация таблицы
2.2.3 Определение отношений между таблицами БД и условий целостности данных
В ходе создания проекта были созданы следующие отношения между таблицами БД
В работе реализованы триггеры Update, Delete, Insert, которые позволяют централизованно обрабатывать события, возникающие при любых изменениях в базе данных. Созданы хранимые процедуры, которые являются частью базы данных и могут использоваться при описании таблиц для проверки введенных данных, определения значения по умолчанию и т.п.
2.3 Выбор программного и технического обеспечения
автоматизация база данные склад
Для разработки автоматизированной информационной системы, исходя из требований предъявляемых к системе, было выбрано средство Microsoft Visual FoxPro 6.0, как для создания базы данных — СУБД, так и для создания интерфейса пользователя.
Для создания баз данных в настоящее время существует большое количество средств, но Visual FoxPro — самый лучший продукт (даже в «оправе» Microsoft) для разработки приложений баз данных. Во-первых, Visual FoxPro с самого начала был задуман для обработки данных. Во-вторых, Visual FoxPro отличается удивительной быстротой, могуществом и гибкостью.
Это вовсе не означает, что роль, которую играет Visual FoxPro в разработке приложений никогда не менялась. Ведь в мире нет ничего постоянного, а тем более в мире программирования. Тенденции перехода от монолитных одноуровневых приложений к многоуровневым только усиливается. Visual FoxPro можно отнести к среднему уровню (правила бизнеса) в многоуровневом приложении.
Как часть оболочки Visual Studio, Visual FoxPro в настоящее время является частью технологической группы для создания общекорпоративных решений. Дни приложений, создаваемых исключительно в Visual FoxPro (или Visual Basic), сочтены. По мере того, как броузеры, например Internet Explorer, становиться все более высокоорганизованным, внешние интерфейсы GUI стремятся «перерасти» в настоящие броузеры, и для этого есть множество причин. Приложения данных (внутренний интерфейс с источником данных) может быть каким угодно (Visual FoxPro, SQL Server, Oracle или любое другое), а прямо посередине (между внешним и внутренним интерфейсами) «забронировано» место для Visual FoxPro.
Если необходимо разработать приложение и не на последнем месте стоит выгодное вложение денег, то выбор следует остановить на Visual FoxPro.
Данная информационная система выполняет следующие функции:
ведение базы данных с ее корректировкой;
— выполнение различных запросов к базе данных;
— составление отчетов, путем отображение различной информации, полученной из базы данных, на экране / принтере.
Для эффективной работы системы рекомендуется использовать следующие технические средства:
1. 128 Mb оперативной памяти
2. Процессор Pentium Celeron 400 и выше
. Принтер HP DJ 920C A4
4. Наличие Microsoft Visual FoxPro 6.0
5. ОС Windows NT/2000 или Windows 98/ME.
6. Мышь Microsoft Mouse или другое совместимое с ней
. Монитор VGA или с большим разрешением, рекомендуется Super VGA
HDD 40.0 Gb IDE Seagate Barracuda ATA 4 (340824A) UDMA100 7200 rpm
Для нормального закрытия файлов информационной системы при аварийном отключении электроэнергии требуется источник бесперебойного питания.
2.4 Выводы
Одним из условий успешного функционирования базы данных является тщательный анализ входных и выходных информационных потоков, предшествующий построению инфологической и даталогической модели. Он включает описание входных оперативных, условно-постоянных, а также выходных данных.
Цель инфологического моделирования — обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому инфологическую модель данных пытаются строить по аналогии с естественным языком (последний не может быть использован в чистом виде из-за сложности компьютерной обработки текстов и неоднозначности любого естественного языка).
Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты).
Были выявленные следующие данные:
Условно-постоянные данные (справочники):
— Наименование товара,
— Ед. измерения, категория товара,
— Склад (номер склада, или его название),
— Перечень организаций, поставляющих товар и их реквизитов,
— Ф.И.О. кладовщика.
Оперативные данные:
— цена товара,
— количество приход,
— количество расход,
— № накладной,
— дата прихода товара,
— остатки,
— сумма налога [12% от сто-ти товара],
— к оплате [сумма+налог].
— Сумма налога за текущий месяц по приходу и расходу.
— Список категорий товаров, хранящихся на i-ом складе.
— Какой товар на складе находится в минимальном количестве.
— Приходная ведомость по i-му складу за j-ое число.
— Ведомость движения товара (остаток — приход — расход — остаток)] по i-му складу.
— Сведения об общей сумме прихода / расхода товаров в I-ом месяце по категориям.
3. Разработка информационной системы учета товаров предприятия
3.1 Технические возможности программы
Программа имеет следующие возможности:
w Учет
– компьютеров
– принтеров
– Копиров
– МФУ
– Фотоаппаратов
– Телефонов
– Факсов
– Сетевых устройств
– Сканеров
– Мониторов
– Другие устройства (тип устройства можно указать любой)
w Создание пользователей с разными приоритетами
w Загрузка информации о компьютере из отчетов программ Everest Prof или AIDA32 (*.ini)
w Введение двух видов гарантий (на комплектующие и системный блок целиком)
w Добавление ремонтов компьютера (другого оборудования)
w Добавление заметок по устройствам